
ELT with Amazon Redshift – An Overview
If you’ve been in Data Engineering, or what we once referred to as Business Intelligence, for more than a few years you’ve probably spent time building an ETL process. With the advent of (relatively) cheap storage and processing power in data warehouses, the majority of bulk data processing today is designed as ELT instead.
Though this post speaks specifically to Amazon Redshift, most of the content is relevant to other similar data warehouse architectures such as Azure SQL Data Warehouse, Snowflake and Google BigQuery.
Wait! What are ETL and ELT again?
A good time for a quick refresher. First, ETL stands for “Extract-Transform-Load”, while ELT just switches to order to “Extract-Load-Transform”. Both are approaches to batch data processing used to feed data to a data warehouse and make it useful to analysts and reporting tools.
The Extract step is gathers data from various sources so that it can be further processed and stored in the data warehouse. These sources can be anything from a transactional (typically SQL) database to JSON data to flat log files.
The Load step either brings in the raw data (in the case of ELT) or the fully transformed data (in the case of ETL) into the data warehouse. Either way, the end result is data entering the warehouse.
The Transform step is where the raw data from each source system is combined and formatted in a such a way that it’s useful to analysts and any tools they use to explore and visualize the data. There’s a lot to this step regardless of whether you design your process as ETL or ELT.
Choosing Between ETL and ELT
5-10 years back, nearly everyone designed their processing as ETL. This was due to the fact that the systems we used as data warehouses didn’t have the storage or compute power to handle the transform process. Loading in a high volume of raw data into a row-based database didn’t scale well, and at the time you needed all the horsepower from your data warehouse focused on analyzing the transformed data. You instead extracted data from source systems and processed it further before sending the final product (the transformed data) to your data warehouse for storage and analysis.
The majority of today’s data warehouses are built on highly scalable, columnar databases that do a great job both storing and running bulk transforms on large datasets. Why? It will take a future post on architecture to get into details, but for Redshift the reasons are due to the I/O efficiency of a columnar database, data compression, and the ability to distribute data and queries across many nodes that can work together to crunch on a job. Below are some illustrations provided by the AWS docs that show the differences in data storage between row and column based architectures.
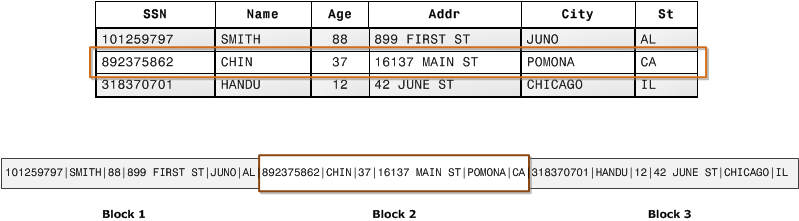
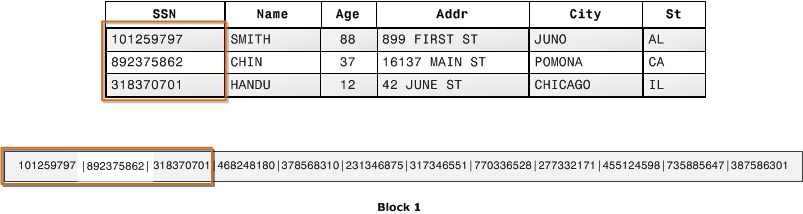
When you choose a columnar based MPP (massively parallel processing) database such as Redshift as your data warehouse, an ELT approach is the most efficient design for your data processing. With a few exceptions*, it’s best to get all your data into Redshift and use its processing power to transform the data into a form ideal for analysis.
*What Exceptions?
There are cases where some transformation of data takes place before it enters your Redshift cluster, even with an ELT design. For example, you might clean up or break apart some strings, such as URLs, in web log data before you send it to Redshift. Some may consider that transformation, others not. It really depends on the data and what processing you already have in place further upstream. I’m no purist, so if you find it’s more efficient to load some “semi-processed” data into Redshift rather than fully raw, that’s fine by me!
ELT Design Overview
Below is a diagram of a simplified ELT process that involves data from two source systems and a Redshift cluster. Below, I describe each step in more detail.
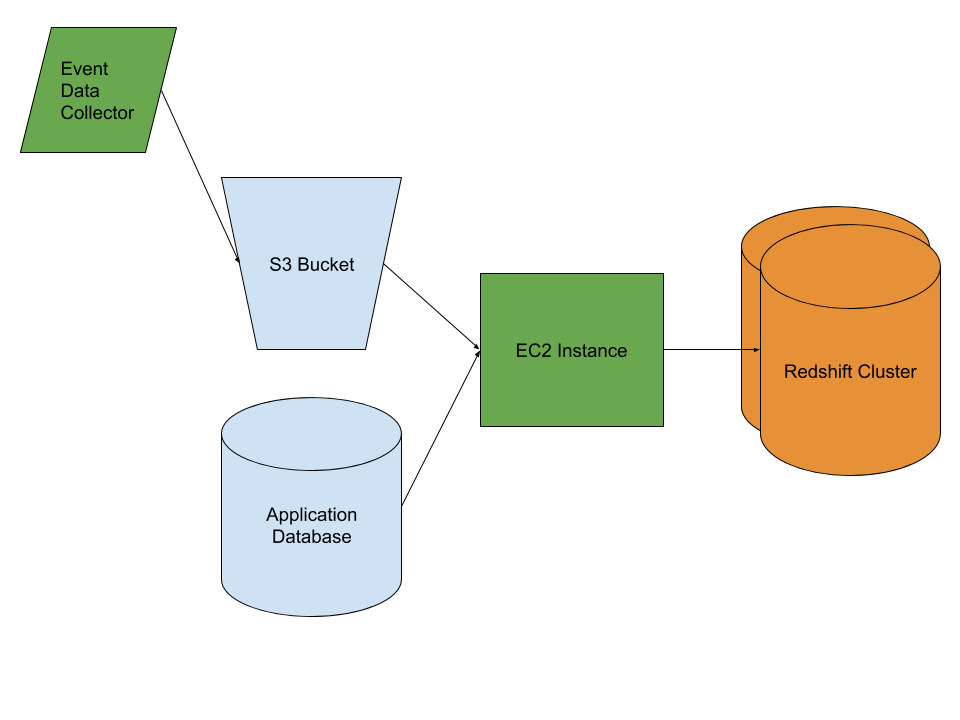
Starting from the left of the diagram, you can see a generic “event data collector” sending some data into a S3 bucket. This represents a common use case where a website’s page views and other events are captured and stored as JSON data, or a sensor’s data is collected and stored in a similar way. The JSON stored in S3 is either semi-processed, or raw. Either way, it’s considered unstructured and is often of high volume. An S3 bucket is a cost effective place to store such data.
On the bottom left is a very typical OLTP database that sits behind some kind of application. Perhaps a web app, or a mobile app. It might be a Postgres, MySQL or Microsoft SQL Server database. OLTP databases contain structured data, and application databases are usually normalized which is great for the applications but not for reporting and analysis.
In the middle of the diagram is an AWS EC2 instance, which you can think of as a virtual machine capable of running the logic behind your ELT process. In this diagram, all of the logic of the ELT process is either contained or controlled by a set of scripts or applications running on the EC2 instance. What you choose to use as your ELT framework, or whether you build or buy is out of the scope of this post but it’s an important topic that I will cover in the future.
For now, let’s say we built our little ELT process ourselves in Python and native Redshift SQL, deployed our Python scripts to the EC2 instance and scheduled them via cron. That’s about as simple as it gets, though as you add more data sources, create more dependencies, and want to depend on logging and monitoring you’ll likely choose an existing framework or product.
Extract and Load
In our simple example, the Python scripts kick off on a schedule (this is batch processing after all) and start the Extraction and Load processes.
For the data in the S3 bucket it might be a simple as executing a COPY command in Redshift to ingest the data into a table. That’s only true if the process which wrote the data to S3 did so in a way that’s prepped for your destination table in Redshift. That’s unlikely, so it will probably take a little Python to parse through the data in the file(s), deal with things like missing fields in the JSON objects, write the resulting data back to S3 and then run a COPY so Redshift can pull it all in.
For the data in the in the application database, you’re essentially taking a copy of the data in each of the tables you’re interested in and inserting it into corresponding tables in Redshift. However, there are some considerations here:
- Which tables do you need?
- Do you need all the columns from each table?
- Do you need to bring in a full copy of the table, or can you only grab the rows that are either new or updated since you last ran your ELT process?
Those 3 questions need to be asked every time you build your ELT processing and as you make changes to your source data in the future. The answers will vary depending on your situation, but here are some things to consider:
- If you aren’t certain that you need a table, it’s best to skip it. You can always come back later. The more tables you have to manage, the more that can break in the future!
- There are several reasons to pick and choose the columns you need from each table rather than taking them all. Data storage and transfer costs, confusion in transformation and analysis, and data privacy.
- The first is straightforward, and many will argue less important unless you’re dealing with a massive application database.
- Confusion is also pretty self explanatory. Applications often store data needed for the operation of the app, but with little or no value to an analyst. By bringing it in, you’re more likely to confuse everyone using the data warehouse than you are the gain any value from it.
- Data privacy/security is an issue that can’t be ignored. Do you need the names and email address of customers stored in your data warehouse? If not, don’t load them in and create more work for yourself. You’ll always need to comply with regulations and contractural agreements related to protecting that data. Sure you can mask fields and manage security in many ways, but it’s not worth the effort if you don’t need the data.
- In order to decide whether to load an entire copy of the table in on each run of your batch, or just grab specific rows you have to understand your data.
- If it’s immutable log-type data such as a table with a row for each time a customer logs in, then it’s easy enough to only pull rows with a login timestamp after the last time you extracted the data.
- What if it’s something like a “Customer” or other entity table? If you can easily identify which rows were inserted or updated since you last checked, then you might wish to only grab those rows and send them to Redshift. Otherwise, you’ll either need to modify your application to add such time-stamping on rows (easier said than done) or grab the table in its entirety and send it to Redshift.
Transform
Once all of the data is loaded into Redshift, then your processing scripts can begin the Transform step. Like the Extract and Load steps, there are numerous ways to implement your Transform step. In this simple example, we’ll have our Python scripts kick off some Stored Procedures, or run individual SQL statements to combine the raw tables and create a set of final tables for use in analysis.
The final table design varies by use case, and is again a topic for another post, but there are some best practices to incorporate into any Transform step:
- Determine what your analysts will doing with the data, and what questions they need to answer. You of course did this before you built your ELT (?!), but one benefit of ELT vs. the old ETL is that you can more quickly turnaround new, transformed data for them. That’s because you’re more likely to have the raw data sitting in the warehouse already. Work with your analysts to identify common queries and aggregations and design your tables to fit those needs.
- Like ETL, star-schemas were all the rage not that long ago, and for good reason. However, beware of the performance hit in querying such a design vs. creating big, denormalized aggregate tables for your analysts to query. Check out this great post on performance comparison between both approaches on Redshift and other MPP databases.
- Consider rebuilding all of your transformed tables completely each day vs. making incremental updates to them. Not only will you reduce complexity in your transforms, but you may even save some processing time. Redshift can handle bulk operations and insert a high volume of records into a table quite efficiently.
A Word About Batch vs. Stream Processing
Though going from ETL to ELT is a step in the right direction, you might also be tempted to move beyond bulk processing all together and go with a real-time, aka stream processing model. There are certainly cases where such an endeavor makes sense, but I’ve found that the majority of such cases involve feeding data into a customer facing application rather than a data warehouse serving analysts. When analysts do need real-time data, it’s often on a small subset and can be handled alongside a batch ELT.
There’s also the fact that a well designed ELT process allows for some data sources to be processed more often than others. As you improve the overall efficiency of your processing, you can bulk process quite often on a robust infrastructure as well.
Want to Learn More?
Keep an eye on this blog for future posts where I’ll go into more depth on each step in a modern ELT process.
One Reply to “ELT with Amazon Redshift – An Overview”
Comments are closed.