
Data Warehouses are the Past, Present, and Future

The death of the data warehouse, long prophesied, seems to always been on the horizon yet never realized. Much like cold fusion power and fully autonomous vehicles, with every advance towards a new world we all get excited only to realize that we’re not quite there just yet.
First it was NoSQL, then Hadoop, then data lakes that would kill the data warehouse. All of those things proved valuable in their own way, yet here we are. Snowflake was the hottest IPO of 2020, and the demand for data and analytics engineers who can crank value out of a data warehouse is as high as ever. How can this be?
First Columnar Then Cloud
In 2010 the future of data warehouses felt pretty bleak. Most analytics teams were relying on a traditional row-based transactional (OLTP) database for their data warehouse. Sure, they might be working with an OLAP Engine such as SQL Server Analysis Services (SSAS) but building those OLAP cubes still required a database to store and “pre-process” the incoming data.
By this point in time, data volume was exploding thanks to ecommerce, social networks, IoT, and more. When it came to processing and querying all that data for analysis, columnar databases came to the rescue.
What’s the big deal about columnar versus row-based databases? Consider a table in the data warehouse with millions of rows. However, for the sake of a given analysis you only need to sum up a single column and filter on another. In a row-based database, data is of course stored in blocks on disk by row. So, when you query you’re reading entire rows, or at least large sections of them, off of disk.
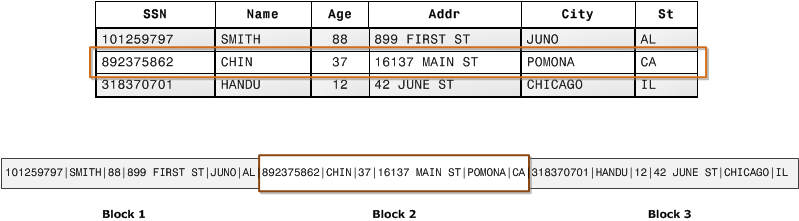
While this architecture makes sense for applications that need to access most, or all, of the columns in a single record, in analytics it’s quite inefficient for both data access as well as storage (if a record is smaller than a single block, or not cleanly divisible by the block size, it leaves some disk space unused).
In a columnar database, data is stored on disk in blocks “vertically” down columns as shown below. When querying a subset of columns as we often do in analytics, there’s less disk I/O as well as less data to load into memory to perform the filtering and aggregation of a query. In addition, data in warehouse tables tend to haev a number of empty (NULL) column values which are more efficient to store in a columnar fashion.
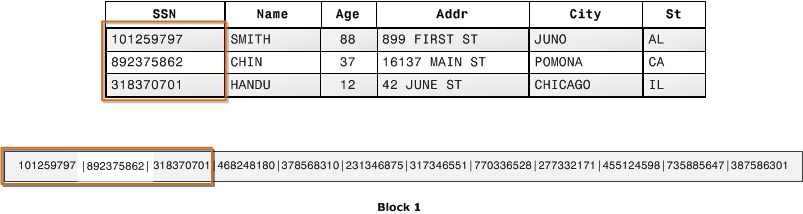
It’s hard to overstate how much of a performance boost you could get off versus the row-based OLTP databases, assuming you properly distributed data across nodes (these systems were, and are today, also multi-node so data could processed by multiple nodes which are clustered together), and wrote queries with the system architecture in mind.
That’s all great architecture-wise, but getting a columnar database in the early 2010s meant investing in some serious bare-metal. For the young folks out there, that means you had to buy a physical server rack filled with what we now refer to as compute and storage. (as an aside, if you’re never had the pleasure of managing physical hardware in a freezing cold server room, find a way to visit a data center. It makes what we do feel more “real”)

While data warehouse “appliances” like the Netezza TwinFin shown above provided a massive jump in processing power, they were quite an investment and expanding meant buying more hardware for your server room. It’s unimaginable 10 years later.
Things changed for the better in 2012, when Amazon launched Redshift. A columnar data warehouse that you could spin up in minutes and pay for in small increments with no massive upfront cost? It’s built on top of PostgreSQL? Amazing! And it was.
I wish I could count the number of migrations away from overtaxed, row-based SQL data warehouses to Redshift that I was either a part of or knew people who were. The barrier to entry for a performant data warehouse was lowered substantially, and suddenly what looked like the impending death of the warehouses was a rebirth. All the glory of Snowflake and other cloud data warehouses built upon that momentum.
ELT Wiped out ETL
I’ve written about the emergence of ELT over ETL before, but here’s a quick refresher about what it’s all about.
Both the ETL and ELT design patterns in analytics include 3 steps:
The Extract step is gathers data from various sources so that it can be further processed and stored in the data warehouse. These sources can be anything from a transactional (typically SQL) database to JSON data to flat log files.
The Load step either brings in the raw data (in the case of ELT) or the fully transformed data (in the case of ETL) into the data warehouse. Either way, the end result is data entering the warehouse.
The Transform step is where the raw data from each source system is combined and formatted in a such a way that it’s useful to analysts and any tools they use to explore and visualize the data. This is where data modeling happens, which is usually performed in SQL (and increasingly within frameworks like dbt).
So the difference between the two patterns is where the T (transform) step takes place, and distributed columnar databases made it all possible. Here’s a bit of what I wrote in my upcoming Data Pipelines Pocket Reference (O’Reilly Media, 2021) on the matter:
Thanks to the I/O efficiency of a columnar database, data compression, and the ability to distribute data and queries across many nodes that can work together to process data, things have changed. It’s now better to focus on extracting data and loading it into a data warehouse where you can then perform the necessary transformations to complete the pipeline.
………
With ELT, data engineers can focus on the extract and load steps in a pipeline (data ingestion) while analysts can utilize SQL to transform the data that’s been ingested as needed for reporting and analysis.
Data Pipelines Pocket Reference, by James Densmore, Published by O’Reilly Media, 2021
In other words, this new breed of data warehouses made it possible (and economical) to store and query far higher volumes of data than ever before. From there, data engineers found they could focus their efforts on efficient ingestion (Extract-Load) of data into warehouses where data analysts could flex their SQL muscles to model the data (Transform) on their own. ELT not only saved the data warehouse, but it lead to the restructuring of data teams and the emergence of a new role, the analytics engineer.
Data Lakes Compliment Warehouses
When the concept of a data lake was first introduced in 2011, some in the analytics industry saw it as the beginning of the end of the structured data warehouse. Turns out, data lakes didn’t wipe out data warehouses. However, they haven’t gone away either. The benefit of storing vast amounts of data without having to define structure when it’s stored (schema-on-write), but rather when it’s queried (schema-on-read) is real. However, there’s a cost to such an approach when it comes to data discovery and governance, as well as in complexity to the data analytics or analytics engineer who works with the data. (the benefit of data lakes for machine learning engineers, and some data scientists, is perhaps a bit higher than it is for analytics engineers)
With the cost of storing and querying large structured datasets dropping and the performance spiking upward thanks to cloud data warehouses, some of the downsides of data lakes for analytics became more noticeable. For most data teams, there just wasn’t reason to give up the benefits of having their data in the familiar table structure of a warehouse.
Still, data lakes have a place in an analytics infrastructure. There’s still a need to store data that’s not consistently structured, or in a volume that makes even the most robust data warehouses creak. However, for most data teams, data lakes have been a compliment to their data warehouse rather than a replacement. In fact, most modern data warehouses provide ways to query data from a lake through the warehouse itself. Some examples include External Tables in Snowflake and Amazon Redshift Spectrum. Methods like those blur the line between a lake and a warehouse when it comes time to query your data. Both have a place, but the warehouse remains the storefront for analytics.
A Long Way to Go
By no means is any prediction safe, and while I can’t see decades into the future I feel quite comfortable in saying that data warehouses aren’t going anywhere anytime soon. Snowflake continues to blow away expectations for developers and investors alike, and I expect a wave of data warehouse innovation from Amazon, Google, and others in the near future.
For those hesitant to invest in a greenfield data warehouse, migrate a legacy one to a modern platform, or hire up data engineers with data warehousing know-how, don’t fear! You’re building for now and investing intelligently for the future.
Cover Image Credit: https://pixabay.com/users/mcmurryjulie-2375405/