
Modular ELT

A while back, I wrote a post on why ELT is preferable to ETL with Amazon Redshift and other modern data warehouses such as Snowflake and Google BigQuery.
Making the case for ELT is hardly a tough sell nowadays. However, as you’ll see in this post there’s no single platform to build an entire ELT process. Data teams are forced to piece together products to get the job done and risk creating overlapping dependencies between them. Doing so is problematic in that it limits an organization’s ability to scale technically and in team structure. A modular approach to ELT is a cleaner design that improves the current and future prospects of a data team.
Please note that while I use many of the products listed below, I do have any affiliate or other compensation agreements with any.
ELT vs ETL
In the post I linked above, I described what ELT is and how it differs from ETL. For reference, I’ll provide an overview here as well.
ETL stands for “Extract-Transform-Load”, while ELT just switches to order to “Extract-Load-Transform”. Both are approaches to gathering and processing data for use in a data warehouse and downstream reporting and analysis needs.
The Extract step gathers data from various sources so that it can be further processed and stored in the data warehouse. These sources can be anything from a SQL database to JSON data to flat log files.
The Load step either brings in the raw data (in the case of ELT) or the fully transformed data (in the case of ETL) into the data warehouse. Either way, the end result is data entering the warehouse.
The Transform step is where the raw data from each source system is combined and formatted in a such a way that it’s useful to analysts and any tools they use to explore and visualize the data.
So while both ETL and ELT perform the same high level functions, they do so in a different order. Again, please refer to my previous post as to why ELT makes sense in modern data warehouses.
A Modular Approach
In addition to taking advantage of technical optimizations described in the following sections, ELT presents new opportunities to organizations –
- Flexibility in choosing and changing products and vendors.
- Cleanly splitting the responsibility of moving data (Extract, Load) and modeling data (Transform) between data engineers and analysts.
In the following sections, I describe some common architectures for Extract, Load and Transform responsibilities along some key decision points for each. I also discuss how it all fits together while providing the benefits promised.
Extract and Load
In ELT, the extract and load steps are often built with the same toolsets and by the same people. Sometimes this is referred to as “data pipelining”. The idea is to extract data from source systems and load it into the data warehouse. Some data teams write custom code to make it all happen, others use commercial tools, and some a mixture of both.
Here is one common architecture I’ve come across. It utilizes open-source products and AWS infrastructure (though the same design applies to Azure and Google Cloud) –
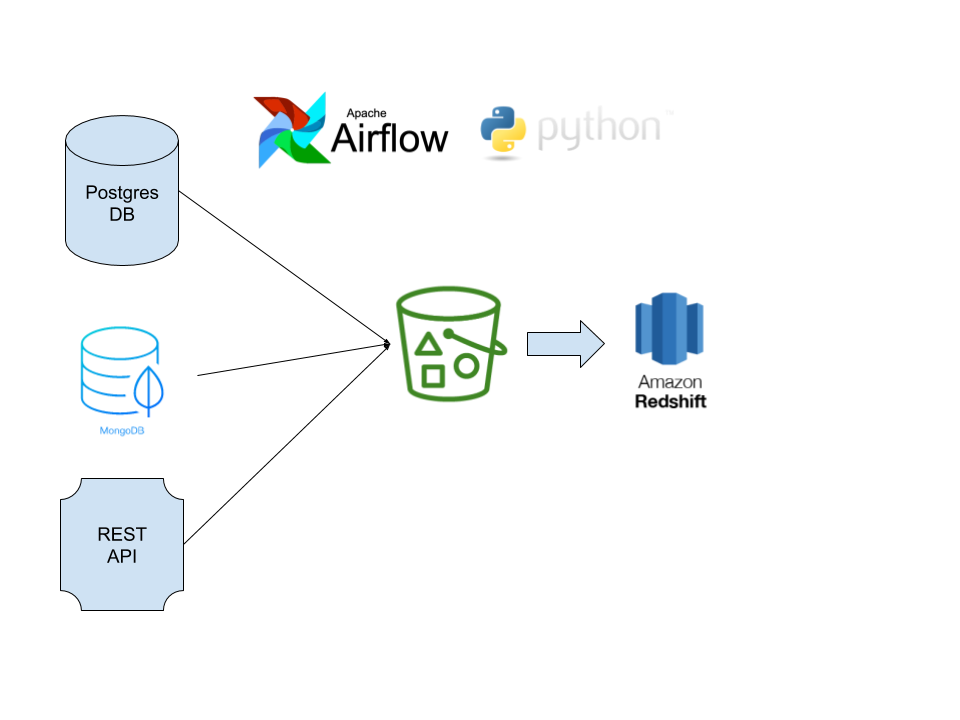
In this example, the data engineering team is using Python scripts to extract data from a REST API, a MongoDB collection and a Postgres database. The data from each extract is written as flat files (often CSV) in a S3 bucket. The load step utilizes the COPY command of Amazon Redshift to load the data from each file into tables in the Redshift warehouse. Each step of this process is scheduled, orchestrated and monitored using Apache Airflow.
If it sounds like a lot of work, it is! However, many companies go in this direction to save money on the cost of software. Now let’s take a look at an example of the same extract and load process using a common commercial product called Stitch.
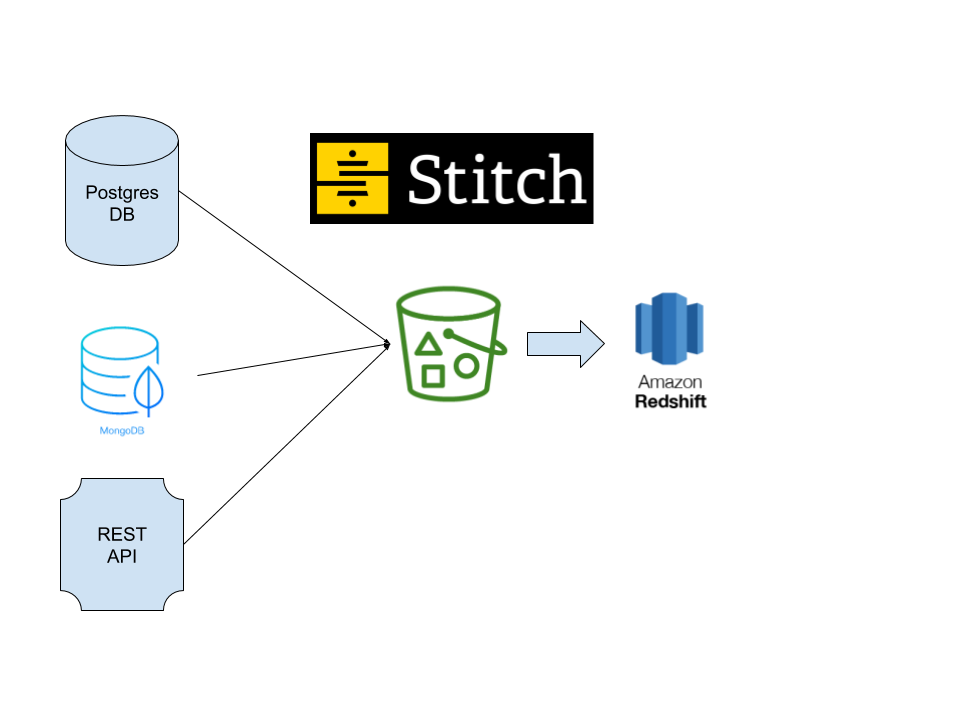
As you can see, data is still being extracted from the same sources and loaded into the Redshift data warehouse. The difference is the lack of any custom Python scripts and Apache Airflow. That’s because Stitch enables the data engineer (or even a less technical Analytics Engineer) to define and schedule data extracts and loads via a web interface hosted by a vendor. Of course this comes at a cost, but Stitch and similar tools like Fivetran are quite popular for a reason. There’s a lot going on in those Python scripts in the first example. Dealing with both structured and unstructured data, full vs. incremental loads, and other nuances is a headache that many are willing to pay a vendor to avoid.
Whether you build, buy or do a combination of both the extract and load processes are often built in tandem.
Transform
In the days of ETL, not only were extracts and loads separated from each other but data was transformed and modeled for consumption by analysts in a different way.
Back then star-schemas were all the rage, but no more. Legacy data warehouses were built on an entirely different technology. Snowflake, Redshift, BigQuery and other MPP (massively parallel processing), columnar databases are better optimized for querying data that has been transformed into single denormalized, large tables both in depth (number of records) and width (number of columns). No longer is joining fact and dimension tables ideal for analysis on these platforms, and neither is the complexity of building and maintaining star-schemas during the transform step.
Where does this leave us? We now have the opportunity to allow the data engineering team to focus on extracting and loading data into the data warehouse and leaving it to data analysts or analytics engineers to do the rest.
At the end of the day, a transform is simply taking data from multiple source tables in the warehouse and denormalizing into the one-big-table (OBT) approach outlined above. For example, perhaps you wish to provide analysts an easy way to report on the number of orders placed by each customer. There are two source tables, “Customer” which has some attributes like the customer’s name and location, and “Orders” which has a record for each order placed. You can create a transform that runs the following SQL to create a CustomerOrders table for analysis.
INSERT INTO CustomerOrders (CustomerId, CustomerName, TotalOrders, .....)SELECT c.CustomerId, c.CustomerName, Count(Distinct o.OrderId), .....FROM Customer cINNER JOIN Orders o on o.CustomerId = c.CustomerId ......WHERE ....GROUP BY c.CustomerID, c.CustomerName;
In reality, each transform is much more complex involving many source tables, SQL functions and dependencies on intermediate tables that bridge the gap between source tables and the final tables created for analysis (often referred to as data models).
Like extracts and loads, there are a few ways to implement transforms. Some teams decide to write a bunch of SQL statements and schedule them to run in sequence after the Load step is completed. This can be done using Airflow like our first example above, or with any other job scheduler. Unless you have a simple warehouse and very few models, you can imagine the headache of dealing with dependencies between source tables and models.
One tool that’s quite popular for the Transform step is dbt. In their words –
dbt is a command line tool that speaks the preferred language of data analysts everywhere—SQL. With dbt, analysts take ownership of the entire analytics engineering workflow, from writing data transformation code to deployment and documentation.
In other words, instead of keeping track of lots of independent SQL queries you can use dbt to define your models and let it worry about interdependencies and other complexities of your transforms.
Whatever tool or approach you take, in modular ELT it’s important to pick one that enables your analysts to take ownership of the transform step.
The Data Warehouse
No matter which data warehouse platform you’re using, “ownership” of the warehouse can be a challenge when different teams own Extract/Load and Transform duties. How you handle ownership is a result of team process as well as technology. Define process, and then leverage the features of your chosen warehouse platform to help enforce it.
As far as technology goes, each of the popular platforms offer different ways to define ownership of objects in the database. Those using Redshift and BigQuery often load data in a “staging” schema and place the data models produced in the transform step into a “modeling” schema. With Snowflake, a team might create different warehouses for each team and even multiple per team.
Modular ELT Principals
As previously stated, we have two goals with modular ELT.
- Flexibility in choosing and changing products and vendors.
- Cleanly splitting the responsibility of moving data (Extract, Load) and modeling data (Transform) between data engineers and analysts.
With the more specific examples above in mind, flexibility might mean moving from a custom Extract/Load in Python to a commercial product like Stitch. Or perhaps you’d like to move from Redshift to Snowflake. Maybe you need to scale up your analysis capabilities but don’t want to hire more data engineers to do so. Though no change is without investment, consider the following principals of modular ELT to make it easier.
- Beware of using the same orchestration and scheduling workflows that you do for the Extract and Load steps for your Transforms. For example, you might be tempted to chain the transforms for each data model as operators in the same DAG in Airflow. As soon as you do, the data engineers and analysts will find their work painfully intertwined. Coordinate, but don’t create tight coupling.
- Clearly define which team owns testing and data validation at each point in the process. For example, there are certain validity checks such as checking for duplicate keys and for unexpected data volume. Put that on the team that owns the Extract and Load steps (usually Data Engineering). Assign validation on the final data models to the team that owns the Transforms.
- Choose tools that offer flexibility. Among other things, one reason teams choose a product like Stitch is the large number of data sources and destinations it supports. dbt is great because you can focus on writing great data models for any data warehouse platform. If you write custom code, do your best to create some abstraction between your code and external dependencies. They will change!
- Don’t prematurely optimize, but assume you’ll need to scale in the near-future. This is a both luxury afforded by modular ELT as well as a principal. Knowing that you can more easily swap out portions of your ELT process means that you can start with simpler and more affordable components and upgrade each individually as you scale. The same goes for your team. Maybe you need to pay more for commercial tooling before you can hire a data engineering team, but want to have the option to customize in the future when a team is in place.
Final Thoughts
A lot of the principals of modular ELT are the same as those for building complex software products. The difference, and opportunity, I see for data teams is two-fold. First we can bring together engineers, analysts and other data specialists efficiently. Second, the technology is finally available at an affordable cost to build a data infrastructure that supports your needs today and in the future with far less risk than ever before.